
| 雲端運算(Cloud Computing) |
|---|
其概念結合了IaaS、PaaS、SaaS、Web 2.0和其它相關技術(如MapReduce、Ajax、虛擬化),共同在網際網路架構上,來滿足使用者在運算資源的高度需求。目前雲端運算有各家專業研 究機構分別提出了不同的定義,如表1所示。

雲端運算不是一項新興技術,而是一種過去就有分散式運算(Distributed Computing)的形式,與代表多台電腦同時進行運算與叢集運算(Cluster Computing)的概念類似,皆是指透過整合大量電腦的運算資源來處理運算需求。
不過叢集運算多為硬體業者採用,強調同一資料中心中的大量電腦;雲端運算則納入網際網路的概念,由遠端網際網路上的伺服器群進行資料的存取與運算,由於這 些伺服器群可能分散在各處不同的資料中心,同時處理來自各地成千上萬使用者的需求,從使用者的觀點來看,根本無從分辨是哪一台伺服器處理了自己送出的運算 需求,如同把需求送入模糊的雲朵中一般,因此便將這種分散式運算模式稱為雲端運算。
諸如Google、Yahoo和Amazon等大型網路公司,由於財力雄厚,可以採購數以萬計的伺服器,叢集便成為一個龐大的運算資源,讓使用者得以透過 網路來存取資料或進行運算,而近年來爆紅的Facebook,也將Hadoop使用在分析Facebook塗鴉牆上某一關鍵詞出現頻率的Lexicon專案,以及改善使用者體驗、搜尋結果等功能上。
雲端服務 vs. 雲端運算
除了雲端運算這項口號之外,還有人提出了雲端服務的概念,這是由於雲端運算通常指的是在網路上提供且為商業和客戶服務的消費模型,這些服務包含了以資訊科 技為主的服務,如軟體即服務(SaaS, Software as a Service)以及提供伺服器運算及儲存能力的服務等,但實際上還有更多和資訊科技無關的商業和客戶的服務,如線上購物、銷售、娛樂等,而這些服務多半 與運算的功能無關,而更為貼近人們的生活,對這些客戶而言,他們所使用的不是雲端運算這項功能,而是由雲端運算環境所提供的雲端服務。
若要更明確的定義這兩者的區別,雲端服務專注在藉由網路連線從遠端取得服務,如提供使用者安裝和使用各種類型作業系統的Amazon EC2服務。這類型的雲端運算可以視為軟體即服務概念的延伸,利用這些服務,使用者甚至可以只靠一支手機做到許多過去只能在個人電腦上完成的工作。
雲端運算則是著眼於利用虛擬化以及自動化等資訊技術,來建構和普及電腦中的各種運算資源,這種類型可以視為傳統資料中心(Data Center)的延伸,且不需要經由第三方機構提供外部資源,便可套用在整個公司的內部系統上。
IDC研究機構則針對雲端服務和雲端運算提供了更清楚的定義,所謂的雲端服務應該有如表2的特性。

透過這些特性,可讓雲端服務的提供者和消費者享受到比起傳統服務遞送模式更為簡易且便宜的優點,這些特性可以降低花費,加速服務遞送的速度,簡化存取的方式,大量增加可用服務的數量和內容,並增進了服務整合性的可能。
雲端運算包含了六種特性,如表3所示;可提供的遞送模型則有SaaS、PaaS、IaaS等三種類型,如表4;部署模型則有私有雲、社群雲、公眾雲和混和雲等四種類型,如表5。



雲端運算架構
實際上雲端運算就是一種分散式運算的實作模式和概念,透過由網際網路所構成的「雲」中,以動態可擴展性和虛擬化的運算資源來提供Web服務,將龐大而複雜 的運算處理程序自動拆解成無數個較小的子程序,交由多部伺服器所組成的龐大電腦叢集進行分散和平行運算分析後,將處理結果回傳給雲端使用者。
對於這些雲端技術和基礎設施,使用者無須擁有專業知識和任何控制權,透過雲端運算,服務提供者可以在數秒之內,達成處理數以千萬計甚至億計的資訊,達到和超級電腦同樣強大效能的各式各樣網路服務。
提供雲端運算時,會涉及的軟體系統架構,通常涵蓋多重的雲端元件,這些元件會透過應用程式設計介面如Web服務來相互通訊,雲端架構會延伸至用戶端,讓用戶端的瀏覽器和軟體應用程式得以存取雲端應用程式。
軟體應用程式的設計,可透過網際網路隨需使用服務,以雲端架構做為建置基礎的應用程式,是一種基本的運算基礎架構,有需要時才會使用(例如處理使用者要 求);可以隨需獲取必要資源(例如運算伺服器或儲存設備)、執行特定工作,然後放棄不需要的資源,通常會在完成工作後自我處置。
透過雲端運算可以解決與大規模資料處理有關的重大難題,如:
●在不同機器上分配與協調大規模工作、在不同機器上執行程序,並在某一部機器故障時,提供另一部機器以供回復。
●根據動態工作量,自動調整所需資源。
●在完成工作時擺脫這些機器。
●取得應用程式所需的大量機器。
●在有需要的時候取得機器。
組成雲端運算的架構則如圖1所示,由下而上分別為基礎架構平台、儲存服務、平台服務、應用程式服務以及客戶端所組成。基礎架構提供了虛擬化運算、電腦叢集、硬體抽象化、虛擬化等硬體服務功能,以及可由使用者配置的運算環境作業系統、網路,記憶體、磁碟、CPU等設定。
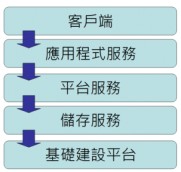
圖1:雲端運算架構。
儲存服務表示雲端上的分散式持續資料儲存,其可能使用不具結構化的傳統式檔案系統來進行資料儲存,例如:HDFS、Key-Object pair、Amazon S3,或者結構化的資料儲存如Amazon SimpleDB、Google AppEngine DataStore;平台服務則是提供開發與執行應用程式服務的雲端平台,例如Google App Engine可讓開發人員在Google的基礎架構上,執行Web應用程式,其中也提供了Java與Python程式語言的執行環境,並完全支援通用的 Web技術與服務,以便用來執行MapReduce應用程式的開放原始碼分散式運算平台;客戶端則是仰賴雲端運算架構來執行應用程式服務,主要操作介面是 透過主流的瀏覽器,如微軟Internet Explorer、Mozilla Firefox、Google Chrome,以及智慧型行動裝置,如Android、iPhone、Windows Mobile。
接下來的文章中將會介紹由Apache所提供開放原始碼的Hadoop雲端運算開發環境,並分別探討在Hadoop中核心的Map-Reduce演算法概念,以及由Hadoop所延伸的HDFS、HBase、Pig、ZooKeeper等套件。
| Hadoop簡介 |
|---|
Hadoop(圖2)命名的概念也非常類似當年Google命名的由來,Google是英文單詞「Googol」按照通常的英語拼法改寫而來的。Googol是一個大數的名稱,也就是10的100次方,表示1後面加上100個零。
 圖2:Hadoop吉祥物。
圖2:Hadoop吉祥物。Hadoop是項目的總稱。主要是由 HDFS 和 MapReduce 組成。HDFS 和 MapReduce 是完全獨立的,並不是沒有HDFS就不能MapReduce運算。Hadoop 的目標是實現海量資料計算。因此需要一個穩定,安全的資料容器,才有了Hadoop分散式檔系統。
有個觀念非常重要,Hadoop不是將存儲資料移動到某個位置以供處理,而是將處理移動到存儲。這通過根據集群中的節點數調節處理,因此支持高效的資料處理。
Hadoop的定位是用來處理與保存大量資料的雲端運算平台,目前屬於Apache頂層專案,在Hadoop中包含了最著名的分散式檔案系統(HDFS)、MapReduce框架、儲存系統(HBase)等元件,如圖3所示,以及根據Hadoop延伸發展的其他子專案:
- Hadoop Common: 在0.20及以前的版本中,包含HDFS、MapReduce和其他專案公共內容,從0.21開始HDFS和MapReduce被分離為獨立的子專案,其餘內容為Hadoop Common
- HBase: 類似Google BigTable的分散式NoSQL列資料庫。
- Hive:分散式資料倉儲,透過Hiave可管理存放於HDFS的資料,並提供根據SQL發展的查詢語言來查詢資料,由Facebook貢獻。
- Zookeeper:分散式且高可用性的協調服務,可為建置分散式系統提供分散式鎖定等原始鎖定功能,提供類似Google Chubby的功能,由Facebook貢獻。
- Avro:新的資料序列化格式與傳輸工具,將逐步取代Hadoop原有的IPC機制, 提供高效能、跨語言以及可保存資料的RPC資料序列化系統。
- Pig:超大資料集的資料流語言以及執行環境,可在HDFS和MapReduce叢集環境中執行,為用戶提供多種介面。
- Ambari:Hadoop管理工具,可以快捷的監控、部署、管理集群。
- Sqoop:于在HADOOP與傳統的資料庫間進行資料的傳遞。
- Chukwa:分散式資料收集和分析系統,其會執行收集器以便在HDFS中儲存資料,且會使用MapReduce來產生報表。
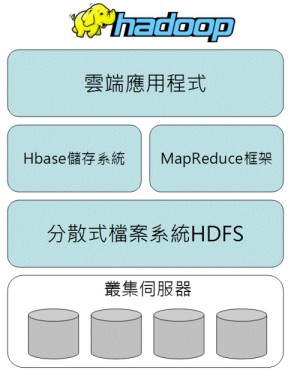 圖3:Hadoop組成元件。
圖3:Hadoop組成元件。Hadoop主要核心完全使用Java開發,而使用者端則提供C++/Java/Shell/Command等程式開發介面,目前可執行於Linux、Mac OS/X、Windows和Solaris作業系統,以及一般商用等級的伺服器。
在Hadoop中最核心的演算法參考了由Google針對大量資料處理所累積的經驗,並於2004年所發表的MapReduce演算法,隔年Doug Cutting隨即公佈Apache Nutch開始採用全新的MapReduce實作。而在2006年Hadoop程式碼從Apache Nutch移至全新的Lucene子專案,2008年Hadoop成為 Apache頂層專案。
► MapReduce
MapReduce誕生源由是Google需要進行大規模資料處理,而在這個過程中,發現了處理大量資料時會面臨某些共同問題,如需要使用許多機器協同計算,以及處理輸入資料時有兩項基本作業:Map和Reduce。
這兩項作業主要是受到函數編程的啟發,以Map/Reduce為基礎的應用程式,能夠運作在由上千台PC所組成的大型叢集上,並以一種可靠容錯的方式平行處理上P級別的資料集。
在函數編程中很早就有了Map和Reduce觀念,其實類似於演算法中各個擊破的作法(Divide and Conquer),也就是將問題分解成很多個小問題之後再做總和。Map函數的輸入是一個鍵/值序對組,輸出則為另一組中繼過渡的鍵/值序對組。而 Reduce函數則負責針對相同的中繼過渡的鍵/值序對組合併其所有相關聯的中繼值,並產生輸出結果的鍵/值序對組,如圖4所示。
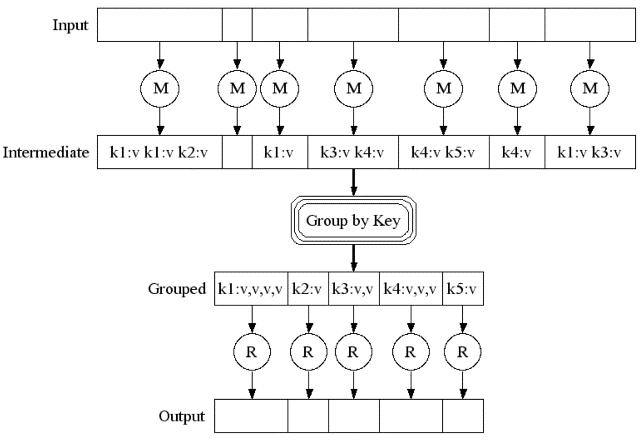
圖4:MapReduce運算方式。
MapReduce則以 JobTracker 節點為主,分配工作(taskTracker)以及負責和用戶程式通信。用戶只要繼承MapReduceBase,提供分別實現Map和Reduce的兩個類,並註冊Job即可自動分散式運行。MapReduce 主要在 org.apache.hadoop.mapred,實現提供的介面類,並完成節點通信(可以不是hadoop通信介面),就能進行MapReduce運算。0.20版本開始引入org.apache.hadoop.mapreduce 的新API
MapReduce則是由Google所發展的軟體框架,目的是對電腦叢集上的大型資料集執行分散式運算,讓使用者可以把心力放在定義Map和 Reduce函數,MapReduce框架會協調機器資源配置並處理的程式輸入、輸入與執行,所有的執行細節交由MapReduce 框架處理。透過 MapReduce可以用於大型資料處理,例如:搜尋、索引製作與排序,大型資料集的資料採礦與機器學習,大型網站的網站存取日誌分析等應用。
► HDFS
HDFS的設計理念是在分散式的儲存環境裏,提供單一的目錄系統 (Single Namespace),一個典型的超大型分散式檔案系統中,通常會有數萬個節點、數億個檔案、以及數十Peta Bytes的資料量,而這樣的分散式檔案系統具備的資料存取特性為Write Once Read Many存取模式。
也就是檔案一旦建立、寫入之後就不允許修改,在這之中,每個檔案被分割成許多區塊(block)與異地備份,每個區塊的大小通常為128 MB,系統會將每個區塊複製許多複本(replica),並分散儲存於不同的資料節點(DataNode)上。
除此之外,HDFS中很重要的概念是其認為移動運算到資料端通常比移動資料到運算端來的成本低,這是由於資料的位置資訊會被考慮在內,因此運算作業可以移至資料所在位置,處理資料的檔案複本預設是每個檔案儲存3份,該設定可由開發人員自訂。
HDFS把節點分成兩類:NameNode 和 DataNode。程式與NameNode通信,然後從DataNode上存取檔。通信部分使用 org.apache.hadoop.ipc,可以很快使用RPC.Server.start()構造一個節點,具體功能還需自己實現。針對HDFS 則為資料流程的讀寫,NameNode/DataNode的通信等
HDFS採用的是一般等級伺服器,因此透過複製資料的方式以因應硬體的故障,當偵測到錯誤時,即可從複製的備份資料執行資料回復。圖5所示為HDFS架構。
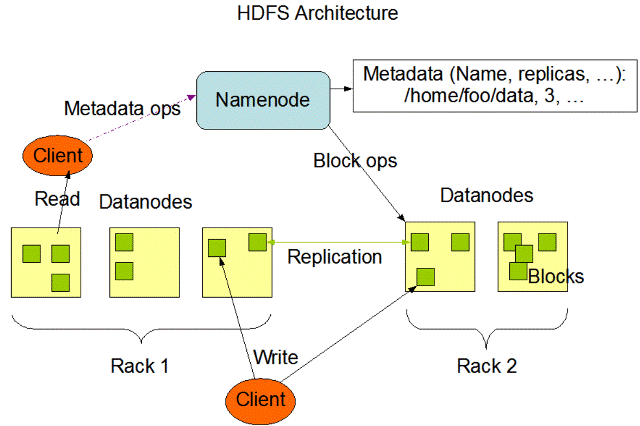
圖5:HDFS架構。
 HBase
HBase簡而言之,HBase的目標是作為Hadoop所使用的資料庫,這可讓我們需要在隨機且即時的讀寫超大資料集時所使用。HBase是一種分散式儲存系統, 其類似RDBM資料表的資料結構(Multi-Dimensional Map),並具備高可用性、高效能,以及容易擴充容量及效能的特性。
HBase適用於利用數以千計的一般等級伺服器上,來儲存Petabytes級的資料,其中以Hadoop分散式檔案系統(HDFS)為基礎,提供類似Bigtable的功能,HBase同時也提供了MapReduce程式設計的能力。
在HBase中使用了和Bigtable非常相似的資料模型,使用者在資料表中儲存許多資料列,每個資料列都包括一個可排序的關鍵字,和任意數目的資料列,資料列的格式會以:來存放。其寫入操作會鎖定資料列,但一次只能鎖定單行資料列,且所有對資料列的寫入操作預設都是原子(Atomic)的。
所有的更新操作都有時間戳記(Timestamp),HBase對每個資料列單元,只會儲存指定個數的最新版本。客戶端可以查詢從某個起始點的最新資料,或者一次得到所有的資料列版本,圖6所示為HBase架構,未來會陸續在專欄文章中進行更深入的探討。
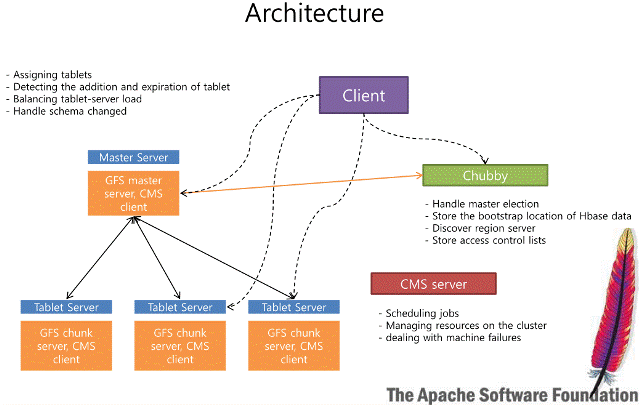
圖6:HBase架構。
from http://www.runpc.com.tw/content/cloud_content.aspx?id=105318
