
| HDFS |
|---|
存儲在 HDFS 中的檔被分成塊,然後將這些塊複製到多個電腦中(DataNode)與傳統的 RAID 架構大不相同.塊的大小(通常為 64MB)和複製的塊數量在創建檔時由客戶機決定.NameNode 可以控制所有檔操作.HDFS 內部的所有通信都基於標準的 TCP/IP 協議. 通信部分使用 org.apache.hadoop.ipc,可以很快使用RPC.Server.start()構造一個節點,具體功能還需自己實現.
NameNode
- 通常在 HDFS 實例中的單獨機器上運行的軟體. 它負責管理檔系統名稱空間和控制外的訪問. NameNode 決定是否將檔映射到 DataNode 上的複製塊上(預設為3塊),第一個複製塊存儲在同機的不同節點上,最後一個複製塊存儲在不同機的某個節點上.
- 實際的 I/O動作並沒有透過 NameNode,只有表示 DataNode 和塊的檔案映射的資料才透過 NameNode.當外部發送請求要求創建檔時,NameNode 會以塊標識和該塊的第一個副本的 DataNode IP 位址作為回應.這個 NameNode 還會通知其他將要接收該塊副本的 DataNode.
- NameNode 在 fsImage 檔存儲所有關於檔案系統名稱空間的信息和一個記錄檔(這裏是 editLog), 這兩檔案存儲本地系統上. 另也需要複製副本,以防檔損壞或 NameNode 系統丟失. NameNode本身不可避免地具有SPOF(Single Point Of Failure)單點失效的風險,主備模式並不能解決這問題,通過Hadoop Non-stop namenode才能實現100% uptime可用時間.
- 通常也是在 HDFS實例中的單獨機器上運行的軟體. Hadoop 集群包含一個 NameNode 和大量 DataNode.
- 回應來自外部的讀寫請求. 也回應來自 NameNode 的創建、刪除和複製塊的命令. NameNode 依賴來自每個 DataNode 的定期(heartbeat)消息. 每條消息都包含一個塊報告,NameNode 可以根據這個報告驗證塊映射和其他檔系統元資料. 如果 DataNode 不能發送定期消息,NameNode 將採取修復措施,重新複製.
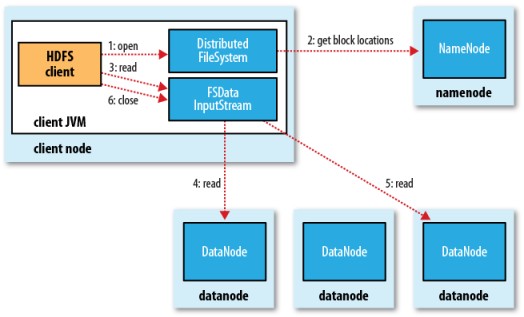
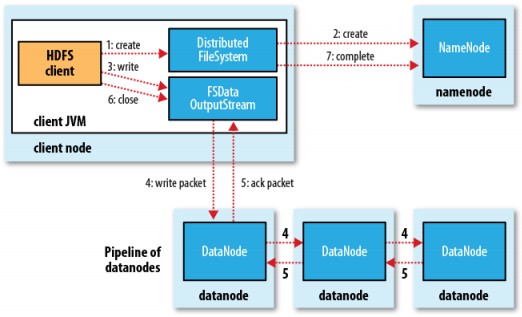
HDFS 不是一個萬能的檔系統. 它主要目的是支援以流的形式訪問寫入大型檔案. 如果客戶機想將檔寫到 HDFS 上,首先需要將該檔緩存到本地的臨時存儲. 如果緩存的資料大於所需的 HDFS 塊大小,創建檔的請求將發送給 NameNode. NameNode 將以 DataNode 標識和目標塊回應客戶機. 同時也通知將要保存檔塊副本的 DataNode.當客戶機開始將暫存檔案發送給第一個 DataNode 時,將立即通過管道方式將塊內容轉發給副本 DataNode.客戶機也負責創建保存在相同 HDFS名稱空間中的校驗和(checksum)文件.在最後的檔塊發送之後,NameNode 將檔創建提交到它的持久化元資料存儲(在 editLog 和 fsImage 文件)
系統參數
fs.default.name 指定連接接口 (如 hdfs://localhost/)
dfs.replication 指定副本(datanode)數量, 預設為3, 單機模式時需設為1
dfs.replication.min 只要寫入的副本數達到此要求即算寫入完成, 縱使沒有達到 dfs.replication 要求數量, 系統內部會自動複製以滿足要求數量
dfs.permissions 權限
dfs.replication 指定副本(datanode)數量, 預設為3, 單機模式時需設為1
dfs.replication.min 只要寫入的副本數達到此要求即算寫入完成, 縱使沒有達到 dfs.replication 要求數量, 系統內部會自動複製以滿足要求數量
dfs.permissions 權限
► 幾個已經實作的抽象類別 (定義在 org.apache.hadoop 內)
| 檔案系統 | URI scheme | Java implementation | 說明 |
|---|---|---|---|
| Local | file | fs.LocalFileSystem | local端的檔案操作與校驗. RawLocalFileSystem 為無校驗的local 端檔案操作. |
| HDFS | hdfs | hdfs.DistributedFileSystem | HDFS 其結合MapReduce在內. |
| HFTP | hftp | hdfs.HftpFileSystem | 透過 http 讀取(唯讀) HDFS 資訊 |
| HSFTP | hsftp | hdfs.HsftpFileSystem | 透過 https 讀取(唯讀) HDFS 資訊 |
| WebHDFS | webhdfs | hdfs.web.WebHdfsFileSystem | 透過 http 讀寫 HDFS 資訊. 主要取代 HFTP and HSFTP. |
| HAR | har | fs.HarFileSystem | 從其他文件系統建構文件結構資訊. Hadoop 藉此建構來降低 namenode 的記憶體使用 |
| KFS (Cloud- Store) |
kfs | fs.kfs.KosmosFileSystem | CloudStore 類似 HDFS 或 Google’s GFS, 以 C++.撰寫. |
| FTP | ftp | fs.ftp.FTPFileSystem | 讀寫 FTP 文件系統 |
| S3 (native) | s3n | fs.s3native.NativeS3FileSystem | 讀寫 Amazon S3文件系統 . http://wiki.apache.org/hadoop/AmazonS3. |
| S3 (block- based) |
s3 | fs.s3.S3FileSystem | 使用 Amazon S3文件系統, 但採用blocks型態儲存以突破 S3’s 5 GB 檔案大小的限制 |
| Distributed RAID |
hdfs | hdfs.DistributedRaidFileSystem | 提供 RAID 架構的 HDFS. 覆寫設定可由 3 縮 2 以降低空間使用, 但資料遺失機率不會增加. 分散 RAID 叢集需要一個 RaidNode 的程序來維持 |
| View | viewfs | viewfs.ViewFileSystem | 從 client端掛載(mount)其他的Hadoop文件系統. 一般用於建立聯合的 namenode |
►文件讀取流程
org.apache.hadoop.fs.FileSystem
from http://baike.baidu.com/view/908354.htm
