
整個運算基本有三程序所組成, 運用常見範例來了解 MapReduce 運作最基本流程, 首先從整個程序的進入點開始
►MapReduce Driver 整個程序作業配置與啟動
►Mapper 接收由 Job 逐一傳入的每行資料
►Reducer Job 將 mapper 產生的資料集以相同 key 為集合組成 values(Iterable)後, 逐一交給 reduce 處理
►整個 MapReduce 資料處理概念圖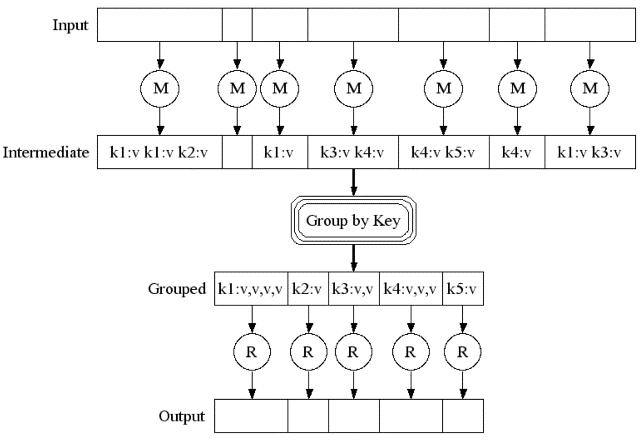 ►其他
►其他
►MapReduce Driver 整個程序作業配置與啟動
public class WordCount { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "Word Count"); //工作配置 job.setJarByClass(WordCount.class); job.setMapperClass(MyMapper.class);//指定讀入數據產生資料集的 Mapper 類別 job.setCombinerClass(MyReducer.class);//非必要, 用來做前置處理以減少資訊量 job.setReducerClass(MyReducer.class);//指定 資料集處理的 Reducer 類別 job.setOutputKeyClass(Text.class);//指定 key 類型 job.setOutputValueClass(IntWritable.class);//指定 value 類型 FileInputFormat.setInputPaths(job, new Path("/data.txt"));//指定資料源,若為目錄則表示要處理該目錄下所有檔案資料 FileOutputFormat.setOutputPath(job, new Path("/out"));//指定最終資料的輸出目錄, 該目錄不可以先存在 System.exit(job.waitForCompletion(true) ? 0 : 1);//執行 } }
WordCount 交由hadoop運作後, job 則自動讀取 data.txt 的內容然後逐行交給 mapper 處理.
假設 data.txt 內容如下
a b c d
a c d
a c d
►Mapper 接收由 Job 逐一傳入的每行資料
public class MyMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); // 實作 map public void map(Object key, Text value, Context context) throws IOException, InterruptedException { //資料處理作為 StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one);//資料存入key=value } }; }
MyMapper.map 將接收到的資料如下, 因檔案共兩行所以會傳入兩次. key 通常為該筆資料在檔案的起始位置, value 則為檔案該行的資料內容.
key=0 values=[a b c d]
key=9 values=[a c d]
map 處理後資料寫入 context, 內容為
key=9 values=[a c d]
map 處理後資料寫入 context, 內容為
[a,1], [b,1], [c,1], [d,1], [a,1], [c,1], [d,1]
►Reducer Job 將 mapper 產生的資料集以相同 key 為集合組成 values(Iterable)後, 逐一交給 reduce 處理
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); // 實作 reduce protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) {//Iterable 只要取出後資料即消失 sum += val.get(); } result.set(sum); context.write(key, result);//結果寫入 part-r-xxxxx 檔內 }; }
MyReducer.reduce 則會接收到如下資料, 雖然map共寫入7筆資料, 但傳給reduce時會將相同 key 組成資料集再傳入, 如此可節省傳遞次數加快處理, 所以reduce僅接收到四筆資料. (注意 key 預設並無排序),
key=a values=[1,1]
key=b values=[1]
key=c values=[1,1]
key=d values=[1,1]
reduce 處理後資料寫入 context, 內容為
key=b values=[1]
key=c values=[1,1]
key=d values=[1,1]
reduce 處理後資料寫入 context, 內容為
[a,2], [b,1], [c,2], [d,2]
完成整個處理作業
►整個 MapReduce 資料處理概念圖
增加輸入檔案過濾機制 FileInputFormat.setInputPathFilter
