
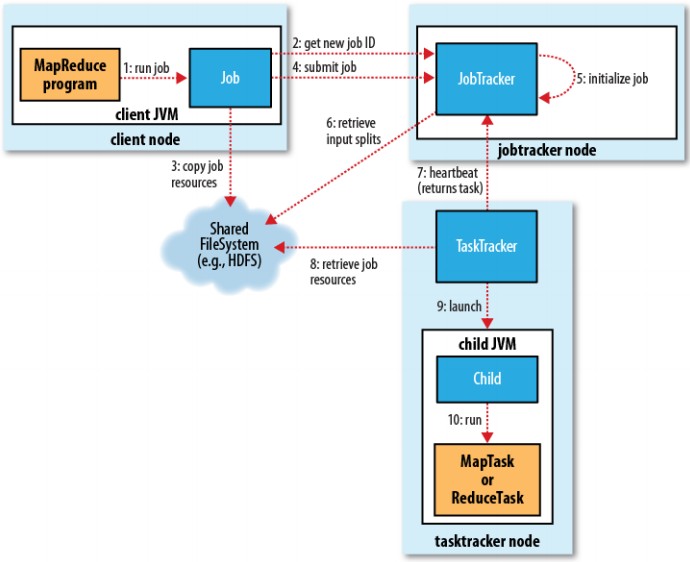
1. 首先進行相關參數, 資源等檢查, 如輸出入目錄,來源檔案等, 無誤後則索取作業ID後, 進行JAR副本後配置.(配置數量參數為 mapred.submit.replication (def 10))
2. JobTracker 接收到 submotJob()後開始 Job初始化並, 然後開始任務配置給 TaskTracker, map 則依資料分段情形進行對應的數量配置 , 而 reduce 則依參數(mapred.reduce.tasks)進行配置.
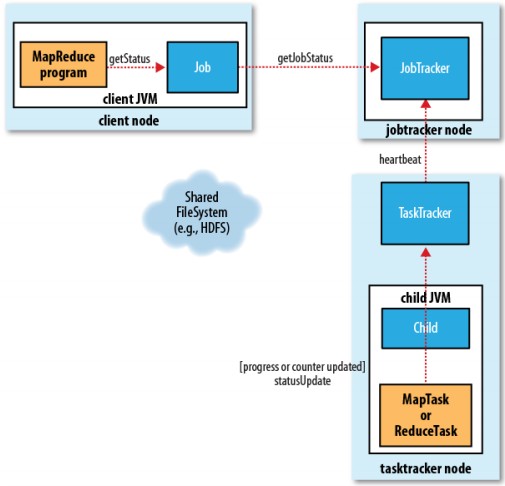
3. JobTracker與TaskTracker則透過heartbeat的交互通訊進行任務執行狀態溝通.
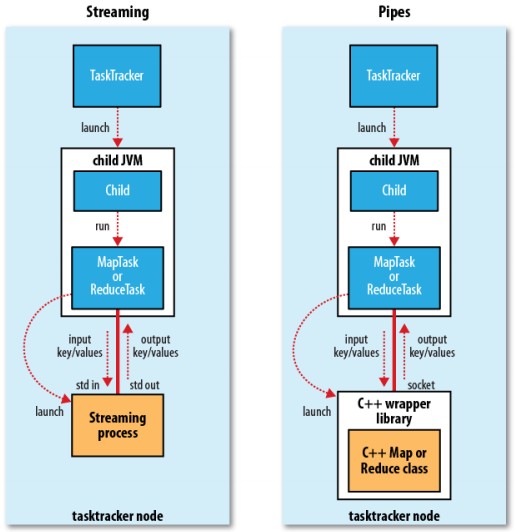
4. TaskTracker 接收到分配後開始進行任務運作.(內部運作通訊機制一般有 streaming, pipes)
7. 當作業有失敗情況發生時, 系統依相關參數進行相關處理.
stream.non.zero.exit.is.failure = true 若程式結束碼不是0, 則表示該定義該程序為失敗狀態
mapred.task.timeout 若任務終止超過時限則jvm將出情該程序
對失聯的 map/reduce 任務最多重新調度次數(通常指heartbeat失聯)
mapred.task.timeout 若任務終止超過時限則jvm將出情該程序
對失聯的 map/reduce 任務最多重新調度次數(通常指heartbeat失聯)
mapred.map.max.attempts , mapred.map.reduce.attempts
容許發生錯誤的百分比, 可避免一有錯誤發生整個程序即終止
mapred.map.max.failure.percent , mapred.reduce.max.failure.percent
mapred.tasktracker.expiry.interval 定義 heartbeat 許可最長的通訊間隔時間, 超過時間未交互通訊則視為失聯
8. 任務優先權
FIFO, 系統預設模式, 透過 mapred.job.priority 或 job.setJobPriority 指派. VERY_HIGH, HIGH, NORMAL, LOW, VERY_LOW, 不過這仍會又先前已運作的任務所影響, 系統不並會去調整以運作任務的資源使用.
Fair Scheduler 是依種增強模式, 可以自動調整運行中任務資源的使用與分配, 要啟用此模式需設定參數
Fair Scheduler 是依種增強模式, 可以自動調整運行中任務資源的使用與分配, 要啟用此模式需設定參數
mapred.jobstracker.taskscheduler = org.apache.hodoop.mapred.FairScheduler
詳細的相關設置與配置可參考 /src/cqntrib/fairscheduler 下的說明文件
Capacity Scheduler 是依種針對多用戶來調度資源分配
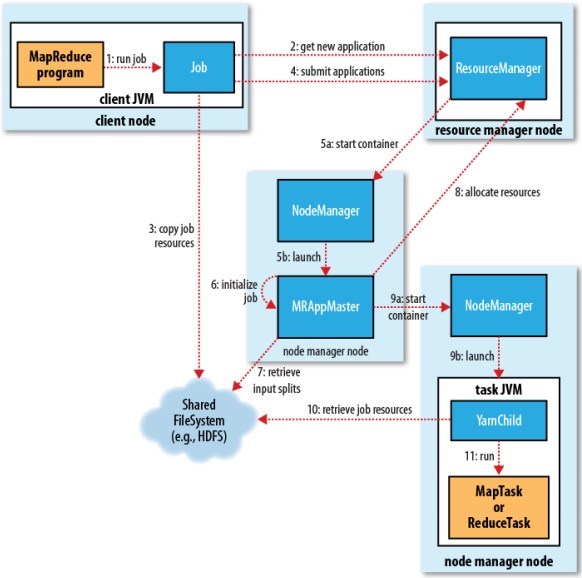
► 第二代 MapReduce YARN (Yet Another Resource Negotiator)的框架如下, 主要增加資源管理能力, 讓其提高處理能力
 |
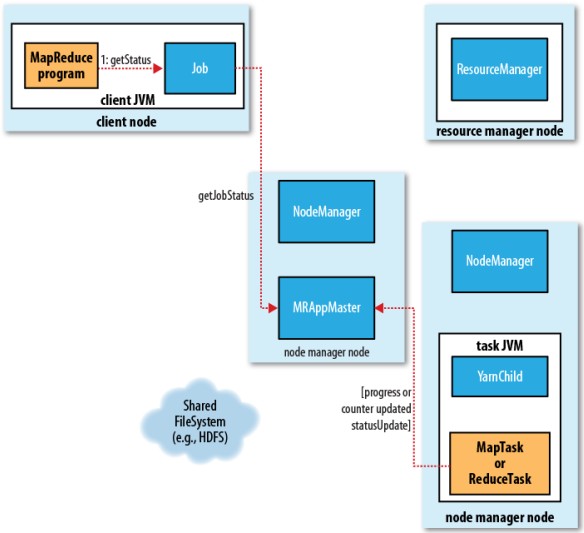 |
| 運作流程 | 狀態回應流程 |
► MapReduce 的混合(Shuffle)與排序 示意圖
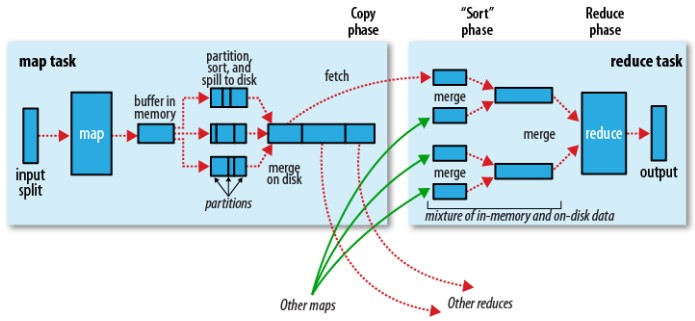
from O'reilly - Hadoop.The.Definitive.Guide
