
MR預設輸出時為以 key 作排序後輸出, 但若相同 key 其 value 並不會進行排序作業, 若需要連同 value 一起排序則需要自己進行, 以下是方法之一, 利用自訂排序類(需繼承WritableComparator)然後透過 job.setSortComparatorClass / job.setGroupingComparatorClass 指定, 但排序對像一樣是 key. 另須注意, 雖然兩個都是ComparatorClass但影響的後續動作卻不一樣
► Sort Driver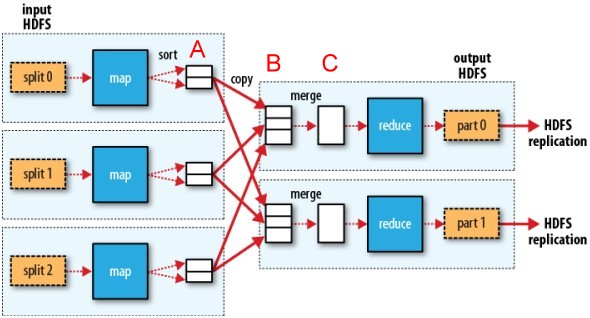
► Sort Driver
► 運作程序依序為 MyMapper -> DataPartitioner -> KeyComparator -> GroupComparator -> MyReducerpublic class MaxSortOutput extends Configured implements Tool { //for setSortComparatorClass 純粹資料排序 public static class KeyComparator extends WritableComparator { protected KeyComparator() { super(DataPair.class, true); } @Override public int compare(WritableComparable w1, WritableComparable w2) { return ((DataPair)w1).compareTo((DataPair) w2); } } //for setGroupingComparatorClass public static class GroupComparator extends WritableComparator { protected GroupComparator() { super(DataPair.class, true); } @Override public int compare(WritableComparable w1, WritableComparable w2) { return ((DataPair)w1).compareKeyTo((DataPair) w2); } } @Override public int run(String[] args) throws Exception { Job job = new Job(getConf(), "Sort Output"); job.setJarByClass(getClass()); FileInputFormat.addInputPaths(job, "/in"); FileOutputFormat.setOutputPath(job, new Path("/out")); job.setMapperClass(MyMapper.class); /*//將map寫入的資料進行分群,Partitioner數受ReduceTasks數量影響 job.setNumReduceTasks(2); job.setPartitionerClass(DataPartitioner.class); */ job.setSortComparatorClass(KeyComparator.class); //排序 map寫入的資料 job.setGroupingComparatorClass(GroupComparator.class); //當回傳值不是 0 時則該筆資料會傳遞給 reduce job.setReducerClass(MyReducer.class); job.setOutputKeyClass(DataPair.class); job.setOutputValueClass(NullWritable.class); return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { System.exit(ToolRunner.run(new MaxSortOutput(), args)); } //分群 public static class DataPartitioner extends Partitioner<DataPair, NullWritable> { @Override public int getPartition(DataPair key, NullWritable value, int numPartitions) { return key.getKey() % numPartitions;//numPartitions值受job.setNumReduceTasks所影響 } } }
DataPartitioner(Partitioner)
用來自訂分群原則, 但可分的群組數受 ReduceTasks 數量所影響, 透過適當的分群可達成不同的排序目標. 另當對大量資料進行分群時, 若各群的數量能夠平均相對整體運作效能較佳. 至於分群原則除自行規劃外, 可透過取樣方法來獲得好的分群方式, hadoop 提供的取樣類有
RandomSampler : 亂數取得資料進行分群計算, 效率較低
IntervalSampler : 固定間距取樣, 適合已排序資料
SplitSampler : 從頭取出 n 個資料進行分群規劃, 因是從頭讀取資料所以不適合已排序資料, 效率較高
IntervalSampler : 固定間距取樣, 適合已排序資料
SplitSampler : 從頭取出 n 個資料進行分群規劃, 因是從頭讀取資料所以不適合已排序資料, 效率較高
KeyComparator(SortComparator)
作用純粹是資料排序, 排序的資料範圍則受 分群 規則所影響, 僅對各自群內資料進行排序
GroupComparator(GroupingComparator)
雖然一樣繼承WritableComparator但實際的影響行為比較像 篩選 因為當傳回值為 0 則資料並不會傳給reducer, 傳回1,-1則會交給reducer處理, 且對資料排序無影響
data flow (from O'reilly - Hadoop.The.Definitive.Guide)
就個人覺得 Partitioner 在A作用, SortComparator與GroupingComparator作用在B或C.比較合理. 至於實際情況因尚未研究過核心程式細節所以就不確定了.
► Map / Reducer
► 資料封裝, 用來將原本的 key, value 放入自訂類以便於排序處理public class MyMapper extends Mapper<LongWritable, Text, DataPair, NullWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String year = line.substring(0, 4); int data = Integer.parseInt(line.substring(11, 15)); //轉由自訂類 DataPair 儲存資料後當key來傳遞,主要目的為能進行兩個欄位進行排序 context.write(new DataPair(Integer.parseInt(year), data), NullWritable.get()); } } public class MyReducer extends Reducer<DataPair, NullWritable, DataPair, NullWritable> { @Override protected void reduce(DataPair key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } }
public class DataPair implements WritableComparable<DataPair> { private int key; private int value; public DataPair() {} public DataPair(int key, int value) { this.key = key; this.value = value; } @Override public int compareTo(DataPair ip) { int cmp = compare(key, ip.key); if (cmp != 0) { return cmp; } return compare(value, ip.value); } public int compareKeyTo(DataPair ip) { return compare(key, ip.key); } private int compare(int a, int b) { return (a < b ? -1 : (a == b ? 0 : 1)); } public int getKey() { return key; } public int getValue() { return value; } @Override public void write(DataOutput out) throws IOException { out.writeInt(key); out.writeInt(value); } @Override public void readFields(DataInput in) throws IOException { key = in.readInt(); value = in.readInt(); } @Override public int hashCode() { return key * 10000 + value; } @Override public boolean equals(Object o) { if (o instanceof DataPair) { DataPair ip = (DataPair) o; return key == ip.key && value == ip.value; } return false; } @Override //輸出格式 public String toString() { return key + " " + value; } }
